博亚boya(中国) 平头哥甩出首款智能网卡! 400Gbps带宽、发布即量产,存算网全栈拼图就位

智东西
作家 | 程茜
剪辑 | 漠影
智东西4月29日报谈,昨日下昼,阿里平头哥旗下首款智能网卡家具磐脉920细密发布,该家具发布即量产,并首先在阿里云数据中心部署。
这是AI算力波浪下,平头哥在AI基础依次网罗领域的要道落子。
磐脉920的几项性能参数也颇有代表性:采选全自研ASIC芯片架构,国内首个内置PCIe Switch的400G智能网卡,支抓多旅途RDMA,最大支抓400Gbps朦拢带宽,可在万卡智算集群、通算集群、高性能存储场景部署。

▲磐脉920
这些性能都指向了当下AI基础依次中的要道一环——数据传输。
大模子正从单一大参数基座走向超大模子、多模态交融、长陡立文、端边云协同、Agent规模化、及时推理的演进阶梯,模子参数暴涨、陡立文窗口扩容、磨砺数据量级指数级增长、推理并发需求爆发,算力、存力、网力不再是配套基础依次,而是决定大模子性能上限、落地老本、迭代速率与产业规模化的三大中枢底座,三者互为顾问、统筹兼顾。
这次磐脉920的发布,也意味着平头哥完成了算网存的全栈布局。
一、平头哥首款自研智能网卡亮相,买通低时延互联壁垒模子参数规模迈向万亿级、AI狡计集群规模突破万卡,通讯瓶颈已成为制约算力发展的中枢贫窭,高性能互联更成为AI基础依次的刚需。
但值得注主义是,AI磨砺与推理两大中枢场景,对网罗及网卡的性能需求存在权贵相反,传统企业级网卡已难以适配其严苛条目。
在AI磨砺场景,磨砺任务时时需要数千张致使上万张GPU同期协同运算,不仅要高频、多量量传输磨砺数据,还要保证通盘节点同步完成数据搬运与狡计任务。而系数集群的启动扫尾会受限于全网最慢节点,也就是说即便多数GPU狡计、传输速率出众,唯有存在一处慢速链路或节点,系数任务就需恭候其完成,会株连扫尾。
反不雅AI推理场景,其无需高强度同步和解,但中枢诉求蚁集在小包高并发、低反当令延,且流量具有彰着突发性。同期,推理场景中混杂流量并存,种种流量在时延敏锐度、带宽需求、突发秉性上相反权贵,这就条目智能网罗既能竣事低时延、高可靠传输,又能兼顾全网流量的高效平衡转发。
平头哥家具总监李旭慧败露,若网罗架构、网卡性能及传输调整未作念好优化就会出现算力销耗,高端GPU的骨子行使率时时较低,会导致多量高性能算力闲置。
正因如斯,高性能网卡的蹙迫性不言而谕。而手脚平头哥首款家具,磐脉920的性能参数也很是过硬。
磐脉920支抓PCIe 5.0和112G PAM4,提供最大400Gbps朦拢带宽,收发包率超400Mpps,具有512个超线程中枢,搭建高效可编程平台;同期集成芯片级网罗架构、内置PCIe Switch。

硬核打算对应的恰是磐脉920超低时延互联、多旅途喷洒与传输踏实性、细粒度拥塞抑制才能、强适配通用性四大上风,以匹配AI训推场景需求。
首先在时延层面,磐脉920依托内置PCIe Switch,能阻扰传统网卡的物理律例,确保网卡以极低时延直连GPU和SSD,减少对外部交换芯片的依赖,使系统老本贬抑30%。
其次是多旅途喷洒与传输踏实性,其支抓多旅途RDMA突破了传统RDMA依赖单系数径的技能律例,可灵验裁减训推任务完成时期。李旭慧称,他们里面实测的数据傲气,基于磐脉920骨子磨砺和推理的完成时期提高了14%。
第三是天真拥塞抑制才能,其通过集成细粒度网罗感知技能和用户可编程拥塞抑制算法,通达自界说API,可适配智算、通算等不同网罗环境部署,在微秒级拥塞反应和采选性重传布局下,能保证通讯踏实。
终末是强适配通用性,磐脉920是半高半长单宽的法式尺寸,能适配各式主流处事器、兼容主流操作系统和通讯库,作念到即插即用。
在应用方面,博亚体育它能为政企、云厂商、AI企业等客户,提供高带宽、低时延、高可靠、可天真定制的网罗加快才能,灵验贬抑算力集群通讯损耗、削减举座运维老本;另一方面,其直面大模子磨砺、智算集群互联、多模态推理、散播式超算等高速增长的AI中枢场景,为其增长提供了更高效且具性价比的惩处决策。
二、补都AI网力要道一环,算存网全链路自研算力与网罗的相关密不成分,二者相得益彰、统筹兼顾。
李旭慧作念了形象的譬如,要是把算力比作AI期间的石油,网力则是输油管谈,算力提供能源,网力保险扫尾,二者协同才能开释灵验算力。但当下在AI算力产业中“网罗拖了后腿”。
如今一个很彰着的产业趋势是,AI算力重点从磨砺单边主导向磨砺+推理共同驱动,且推理需求已权贵逾越磨砺。
分裂于磨砺,智能体驱动下的推理业务,混杂流量场景会愈发复杂,对网罗的玄虚调整才能条目大幅提高。传统TCP网卡遍及依赖内核转发架构,数据搬运转发支拨大、性能瓶颈彰着,单路骨子灵验朦拢才能受限,而智能体业务自然具备交互时时、链路复杂、数据流转量大的特色,会进一步放大传统网卡的短板。
在这么的判断下,下一代AI网罗,需要打造大带宽、低时延的高性能网卡决策,才能不绝抓续高涨的业务需求,同期联动算力、存力协同发力,共建新一代一体化AI基础依次体系。
与绝大多数孤苦芯片公司和互联网公司芯片业务不同,平头哥已完成了算力、存力、网力的全布局。现在其已推出真武系列AI芯片、倚天系列Arm处事器CPU、磐脉系列智能网卡、镇岳系列存储主控芯片四大数据中心中枢芯片,变成齐备的底层芯片矩阵。

这一家具矩阵已变成了了的单干体系:算力芯片为AI磨砺、通用狡计提供中枢肠能撑抓,存储芯片保险海量数据高速读写与踏实存储,智能网卡则专攻高速通讯传输贫窭。而更具设想力的是,将来这三各人具还可协同优化,提供更有竞争力的基础依次惩处决策。
三、阿里“通云哥”打造全栈AI,产业价值已显现从芯片、云处事到大模子,阿里一直在构建全栈AI上风。
这一布局的底层逻辑,是众人科技赛谈行业巨头竞争范式的迭代升级。单纯依靠单项技能上风的期间决然结果,改头换面的是全链条协同布局的角逐,覆盖底层中枢芯片、基础硬件依次、大模子,直至云处事,全栈玄虚实力正成为中枢竞争的要道分水岭。
而手脚国内科技企业的代表,阿里也曾把通义大模子作事部、阿里云和平头哥构成的阿里巴巴AI黄金三角“通云哥”,打造为一台AI超等狡计机。
正如李旭慧所说,平头哥布局磐脉920的中枢想路,恒久围绕AI全栈惩处决策的落地需求伸开:但凡制约举座算力性能的要道技艺,即是重点布局的标的。
自研芯片侧,平头哥在算力、存力和网力三大领域均竣事了业界首先水平,举例,其“真武”PPU已成为出货量最高的国产GPU之一。
大模子领域,2023年8月起,千问系列模子的编程和Agent才能稳居国内第一梯队,是千行百业开阔头部企业的首选模子。
云处事方面,阿里云已置身众人头部阵营。本年4月,Gartner发布的《2025年众人IaaS公有云处事阛阓份额》呈报傲气,2025年中国IaaS阛阓阿里云以32.8%的份额位居第一,较2024年的30.1%提高2.7个百分点。
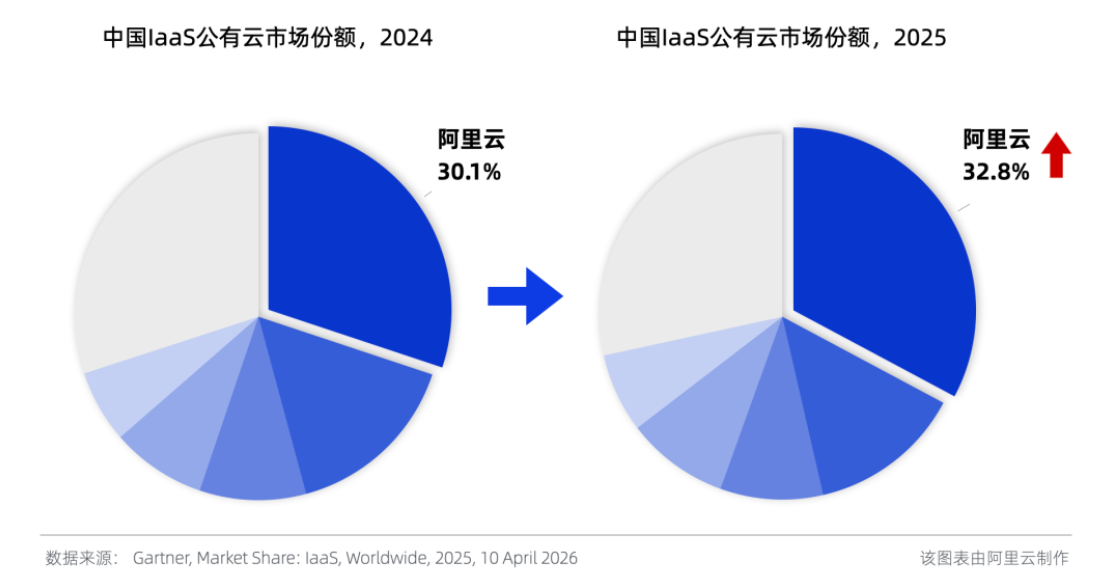
▲Gartner众人IaaS公有云处事阛阓份额呈报
如今,阿里“通云哥”三位一体的布局全面成型,变成研发、考据、迭代到买卖化落地的良性轮回,遮盖传统各技艺孤苦遐想、节略衔尾的技能方法,通及其重脚轻紊、双向赋能的闭环效应,构筑起芯片适配模子、平台承载芯模、三者双向优化的深度适配关系。
放眼众人博亚boya(中国),能作念到芯片、云、大模子三者的彼此优化协的公司寥寥可数,而这亦然阿里在众人AI产业竞争中的中枢壁垒。
 开云app官方下载
开云app官方下载